はじめに
端的に言えば、本稿では、ある特定のwebページから、必要な情報を取り出す方法をまとめる。
具体的にはpythonを使って、京急のwebサイトから運行状況を取得する。
狙いのwebページ上で、必要な情報を特定する方法ですな。
大まかな手順
- 狙いのwebページ上で狙いのデータの住所を特定する
- pythonの対話モードで読めるかどうか実験
- スクリプト化
使うもの
pythonとそのライブラリ、lxmlとrequestsを使う。requestsはいわばブラウザ。htmlをダウンロードする。lxmlはXMLやhtmlを扱うライブラリ。pip listで調べて、なければpip installしておく。
$ pip list
Package Version
----------------- ----------
lxml 4.5.0
requests 2.22.0
ブラウザ。
本稿ではFirefoxを使う。
データの場所の特定方法について
狙いのデータが含まれるHTMLの中の、どこにそのデータがあるか。
いわばデータの住所を知る必要があるのだが、住所の記載方法にはCSSセレクターとXPathという2種類がある。
どちらがよいかは、どうも議論を呼ぶ話題のようだ。
特に主義主張がなければ、データに合わせて、使いやすい、あるいは、特定しやすい方法を選べばよいと思う。
実際のスクリプト上でも命令が少し違うだけだし。
いずれにしても住所はブラウザを使って調べることになるから、両方を調べて後で決めればよい。
データの場所の特定
本稿では京急の運行状況を例として進める。
まず、京急のページを開く。
ここではFirefoxを使っているが、Chromeにも同様の機能はある。
さておき、2020/02/23 00:03付で「京急線は平常通り運転しています。」とある。
この文がターゲットである。
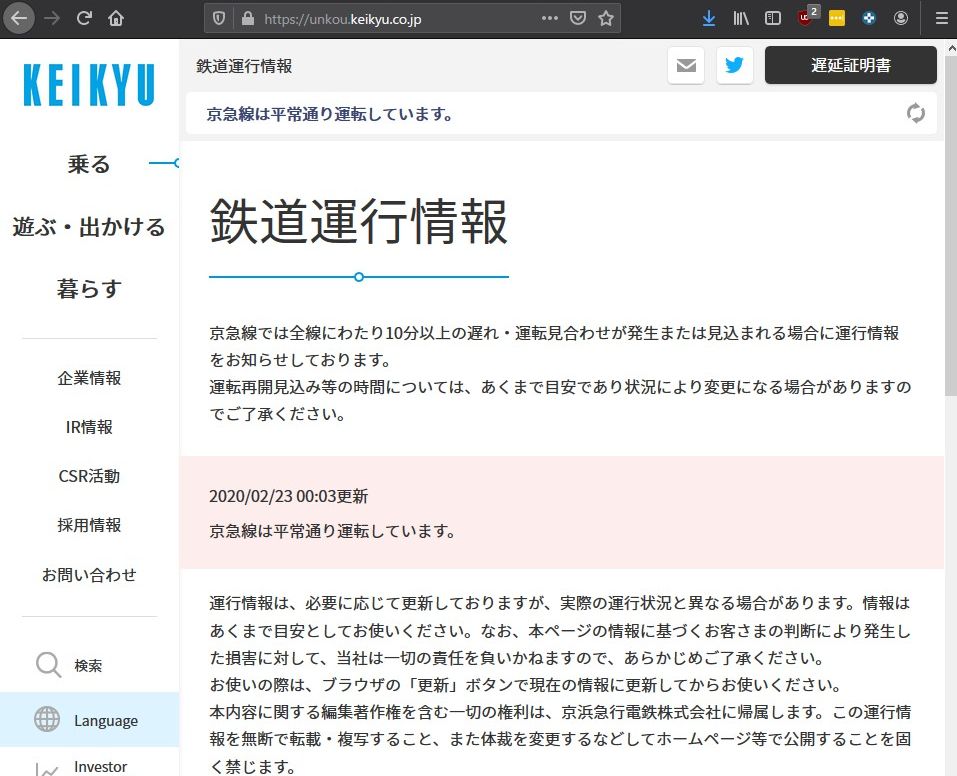
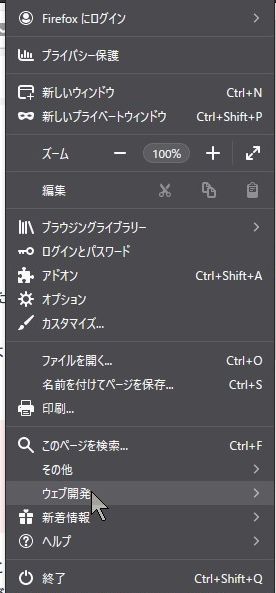
そこでおもむろに右上のメニュー(横棒三本の「三」)から、ウェブ開発、インスペクターを選ぶ。
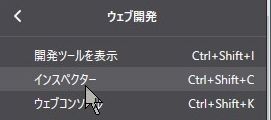
すると画面下のほうになにやらウィンドウが開く。
慌てず騒がず、「京急線は平常通り運転しています。」をクリックする。
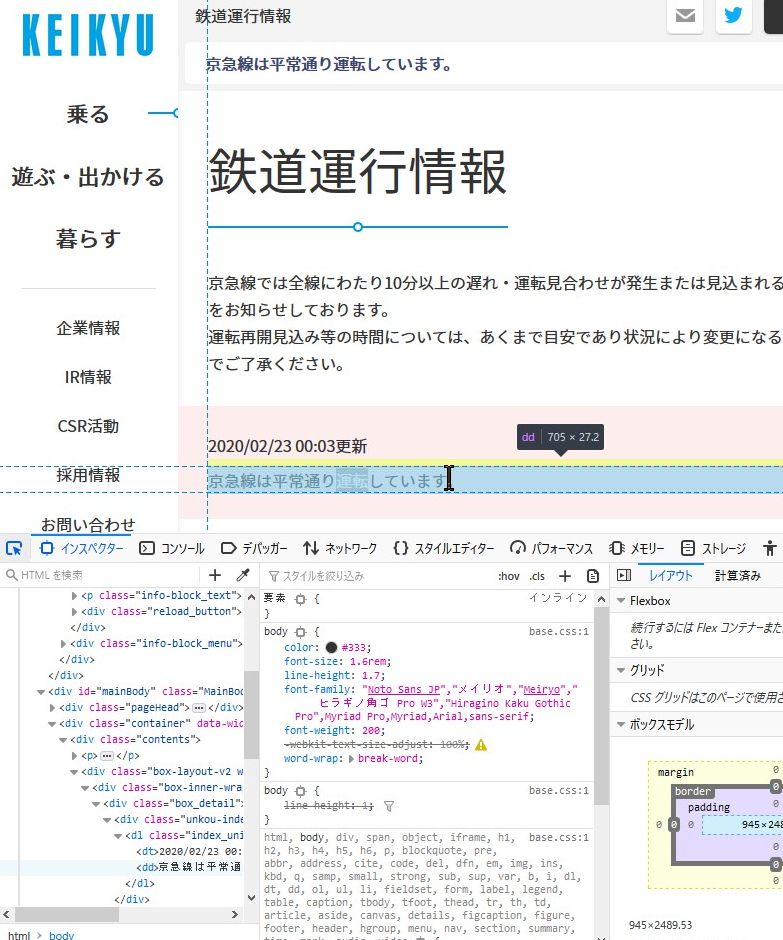
すると画面下にある三つのウインドウのうち、左端の「HTMLを検索」ウインドウでハイライトされる行がある。
そこを右クリックする。
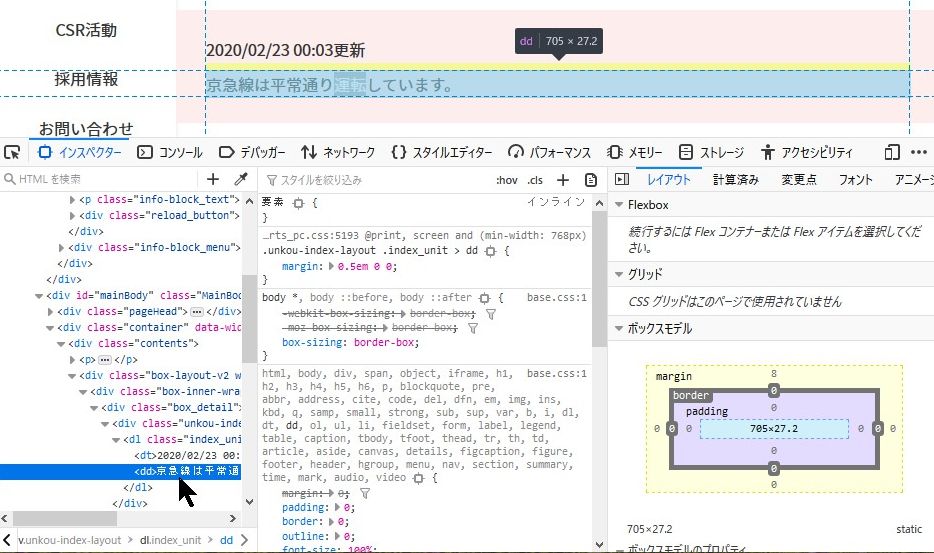
コピー、CSSセレクターを選ぶ。
Xpathでもよい。
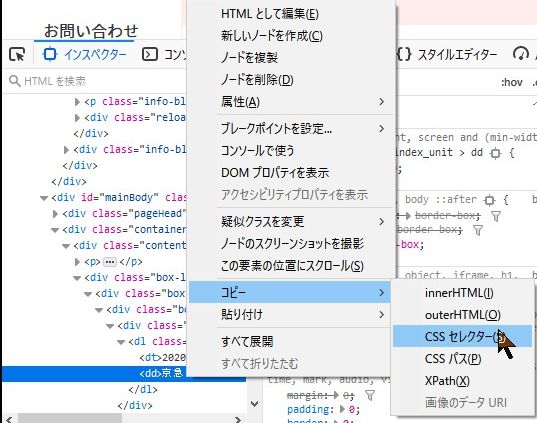
コピーした内容はメモしておく。
cssセレクター
.index_unit > dd:nth-child(2)
xpath
/html/body/main/div[2]/div[2]/div/div[1]/div/div/div/dl/dd
xpathのが長くて見にくいので、CSSセレクターの方を使う。
実験
きちんとしたスクリプトにするのは後にして、まずは実験。
コマンドプロンプトでpythonと叩くか、idleを立ち上げるか、Visual Code Studioのターミナルでpythonと叩くか、好きにしなさい。
まずはrequests, lxmlをimportする。lxmlは、このうちlxml.htmlしか使わない。
>>> import requests
>>> from lxml import html
>>>
urlに京急のwebページアドレスを代入。
代入したらurlリターンで中身がきちんと入っているか確認しようね。
>>> url = 'https://unkou.keikyu.co.jp/'
>>> url
'https://unkou.keikyu.co.jp/'
>>>
requests.get()でhtmlをダウンロード。
HTTPステータスコードが返る。200なので成功だね。
>>> r = requests.get(url)
>>> r
<Response [200]>
>>>
返り値に.textを付けると中身を教えてくれる。
>>> r.text
'<!DOCTYPE HTML>\n<html lang=ja>\n<head prefix="og: http://ogp.me/ns# fb: http://ogp.me/ns/fb# article: http://ogp.me/ns/article#">\n<script async src="https://www.googletagmanager.com/gtag/js?id=G-F2TJL9C6RN"></script>\n<script>\r\n window.dataLayer = window.dataLayer || [];\r\n function gtag(){dataLayer.push(arguments);}\r\n gtag(\'js\', new Date());\r\n gtag(\'config\', \'G-F2TJL9C6RN\');\r\n </script>\n<script>\r\n (function(i,s,o,g,r,a,m){i[\'GoogleAnalyticsObject\']=r;i[r]=i[r]||function(){\r\n (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),\r\n m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)\r\n })(window,document,\'script\',\'//www.google-analytics.com/analytics.js\',\'ga\');\r\n\r\n ga(\'create\', \'UA-61218678-1\', \'auto\');\r\n ga(\'send\', \'pageview\');\r\n </script>\n<meta charset=utf-8>\n<meta http-equiv=X-UA-Compatible content="IE=edge">\n<title>鉄道運行情報 | 乗る | 京浜急行電鉄(KEIKYU)</title>\n<meta name=description content="鉄道運行情報のご紹介。京浜急行電鉄のオフィシャルサイトでは運行状況やご利用案内の他、周辺地域の観光情
ごちゃごちゃしている。
ここでlxmlの出番。lxml.html.fromstring()で、HTMLをパース、解析してくれる(以下の例では事前にfrom lxml import htmlとしているので、html.fromstring())。
返り値はHTML Elementと呼ばれるもの。
詳しくはlxmlのページを。
以下の例では返り値をelemに入れた。
これにtext_content()を付けると中身を教えてくれる。
だいぶ読みやすくなった。
あとはここから運行状況を読み取ればよい。
>>> elem = html.fromstring(r.text)
>>> elem
<Element html at 0x3e3de38>
>>> elem.text_content()
"\n\n\n\r\n window.dataLayer = window.dataLayer || [];\r\n function gtag(){dataLayer.push(arguments);}\r\n gtag('js', new Date());\r\n gtag('config', 'G-F2TJL9C6RN');\r\n
\n\r\n (function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){\r\n (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),\r\n
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)\r\n })(window,document,'script','//www.google-analytics.com/analytics.js','ga');\r\n\r\n ga('create', 'UA-61218678-1', 'auto');\r\n ga('send', 'pageview');\r\n \n\n\n鉄道運行情報 | 乗る | 京浜急行電鉄(KEIKYU)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n乗る\n\n\n閉
じる\n乗る TOP\n\n路線図・各駅情報\nきっぷ・定期券\nPASMO\n京急線アプリ\nウィング号指定券(KQuick)\nKQスタんぽ\n振替輸送のご案内\n鉄道運行情報\n京急線遅延証明書の発行\n京急の電車紹介\n電車内・駅構内に
おける禁煙の取り組みについて\n\n\n\n\n遊ぶ・出かける\n\n\n閉じる\n遊ぶ・出かける TOP\n\nおトクなきっぷ\n羽田空港アクセスガイド\n京急沿線マガジン\nけいきゅうキッズチャレンジ!\nよこすか京急沿線ウォーク\n三浦半島の小さな旅\nもっと楽しむ羽田\n\n\n\n\n暮らす\n\n\n閉じる\n暮らす TOP\n\n京急沿線で暮らす\n\n\n平和島\n大鳥居\n京急川崎\n日ノ出町\n弘明寺\n杉田\n上大岡\n金沢文庫\n追浜\n横須賀中央\n京急久里浜\n\n\n\n\n\n\n\n\n\n企業情報\n\n\n閉じる\n企業情報 TOP\n\nトップメッセージ\n会社概要\n沿革・歴史\n役員一覧\n組織図\nグループ事業のご案内\n不動産の取引に関するお客様の個人情報のお取扱いについて\n各種申込
書や証明書などの個人情報のお取り扱いについて\nニュ
ではここで住所の出番。
さきほどのHTML Elementを.cssselect(住所)すれば、マッチしたところを返してくれる(XPathの場合は.xpath(住所))。
ただし注意しないといけないのは、返り値はリストであること。
いきなり.text_content()を与えても結果は表示されない。
実際に例を示す。
メモしておいた住所をいったんselectorに入れる。
それで.cssselect。
返り値をtemplistに入れて、.text_content()で中身を見ようとしても「リストだからダメ」と怒られる。
>>> selector = '.index_unit > dd:nth-child(2)'
>>> selector
'.index_unit > dd:nth-child(2)'
>>>
>>> templist = elem.cssselect(selector)
>>> templist.text_content()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'text_content'
>>> templist
[<Element dd at 0x41219b0>]
気を取り直して、長さを調べると1。
なので、ピッタリ見つけたようだ。
>>> len(templist)
1
>>>
じゃさっそく[0]を添えて中身を見る。.text_content()を使う。
>>> templist[0]
<Element dd at 0x41219b0>
>>> templist[0].text_content()
'京急線は平常通り運転しています。\n'
>>>
見えた。
無駄な改行コードが入っているので.strip()しよう。
>>> templist[0].text_content().strip()
'京急線は平常通り運転しています。'
>>>
オッケー
スクリプトに
以上の実験結果をもとに、以下の通りスクリプトにした。
ついでに最終更新日時も取得するようにした。
import requests
from lxml import html
def get_keikyu_status(
url = 'http://unkou.keikyu.co.jp/',
status_selector = '.index_unit > dd:nth-child(2)',
update_selector = '.index_unit > dt:nth-child(1)'
):
"""
京急のwebページから運行状況、運行状況最終更新日時を取得し、返す。
引数は無しでもよいが、京急運行状況URL、運行状況を特定するCSSセレクター
最終更新日時を特定するCSSセレクターを引数に取る。
返り値は京急webページそのままのstring。
"""
r = requests.get(url)
elem = html.fromstring(r.text)
status = elem.cssselect(status_selector)[0].text_content().strip()
last_update = elem.cssselect(update_selector)[0].text_content().strip()
return status, last_update
if __name__ == '__main__':
(status, last_update) = get_keikyu_status()
print(status)
print(last_update)
実行結果
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
新しいクロスプラットフォームの PowerShell をお試しください https://aka.ms/pscore6
PS C:\Users\J\Downloads\py\keikyu> & "C:/Program Files (x86)/Python38-32/python.exe" "c:/Users/J/Downloads/py/keikyu/keikyustatus.py"
京急線は平常通り運転しています。
2020/02/23 00:03更新
PS C:\Users\J\Downloads\py\keikyu>
このスクリプトで取得したデータをSlackでもLINEでも送って、スマホに通知したりすればよい。