Hadoopへのノードの追加
hadoopの長所は、処理量に応じて簡単にスケールできる点にある。
処理がおっつかなくなってきたら、データノードを追加するだけ。
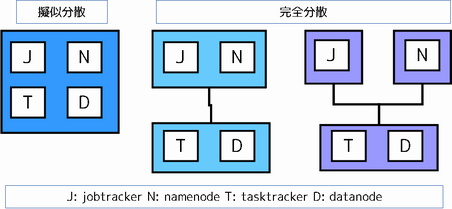
擬似分散モードから完全分散モードへの移行は、データノードの追加と同じ。
もう少し詳しく言うと、最初の1台をnamenode/jobtrackerのままにして、datanode/tasktrackerを追加する。
※FreeBSDで、hadoop-1.0.0です。
背景
namenode, datanodeはHDFSのノード種別を表し、namenodeはファイルのメタデータを扱い、datanodeは実データを扱う。
namenodeはhadoopクラスタに原則1台。datanodeは1台以上必要。
jobtracker, tasktrackerはMapReduceでのノード種別を表し、jobtrackerは作業の分担を、tasktrackerは作業の実施を行う。
jobtrackerはhadoopクラスタに原則1台。tasktrackerは1台以上必要。
hadoopクラスタに参加しているノードは、4つの役割のいずれかを担う。複数の役割をこなすのも可。
ただしdatanodeとtasktrackerは必ずセット。
イメージを示す。
設定ファイル
再掲になるが。
どのノードがnamenodeかを指定するのは、core-site.xml 。
どのノードがjobtrackerかを指定するのは、mapred-site.xml 。
どのノードがdatanode/tasktrackerかを指定するのは、slaves 。
擬似分散モードでは、以上3つのファイルに1ノードしか書かれていなかった。
ノードを追加するなら、slavesにdatanode/tasktrackerを追記すればよい。
擬似分散モードの状態からjobtrackerを分離するには、mapred-site.xmlを書き換えればよい。
擬似分散モードの状態からnamenodeを分離するには、core-site.xmlを書き換えればよいけど、HDFS上にすでにファイルを置いている状態でそんなことするとファイルが吹き飛ぶので止めよう。
そしてこれら設定ファイルは、クラスタ内のノードで同じものを使う。
作業の流れ。
datanode/tasktrackerを追加してみる。
擬似分散モードを仮想マシンで動かしている場合には、それをまるまるコピーしてしまえばよい。
私の場合は、ESXi上でHadoop環境を作ったので、それをコピーし、別マシンのESXiに移し替えた。
もちろんホスト名は別のものにする。
ESXiなどを挟まない場合にはもう一度セットアップ。
ほんとに面倒くさいので、chefやらpuppetなどを使うことになるでしょう。
なお、ESXiは使わない方がパフォーマンスは良い。これは当たり前。
追加ノードの注意点
便宜上、擬似分散モードを動かしたノードをoriginal、追加するノードをaddとする。
addを追加するときの注意点は以下の通り。
/etc/hostsの設定。
original, addの/etc/hostsには、original, addの名前解決ができるようにしておくこと。
時刻同期
original, addで時刻を合わせておくこと。
slavesへの追記
original, addそれぞれでslavesにaddと追記しておく。
SSHログインの確認
originalからaddへsshログインできることを確認しておく。
datanode/jobtrackerの制御はsshでされるため。
replication数の変更
HDFS上でデータのコピーをどれだけ作成するかの設定。
擬似分散ではreplicationを1にしていた。
せっかくなのでこれを2に変更する。
デフォルトは3。
datanodeをさらに増やしたなら、ここの上限をとりあえず3として増やそう。
ノード追加の反映
ノードの追加が初めてならstop-all.shで止めて、start-all.shでまるまる再起動するのがいいでしょう。
当然ながら、hadoop上で何かしらの作業が動いていたらやり直しになってしまう。
通常は、namenodeでhadoop dfsadmin -refreshNodesを実行。
さらにhadoop dfsadmin -reportで確認する。
[hadoop@vfbsd ~]$ hadoop dfsadmin -refreshNodes
[hadoop@vfbsd ~]$ hadoop dfsadmin -report
Configured Capacity: 96683511808 (90.04 GB)
Present Capacity: 57517137920 (53.57 GB)
DFS Remaining: 28587847680 (26.62 GB)
DFS Used: 28929290240 (26.94 GB)
DFS Used%: 50.3%
Under replicated blocks: 5
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 2 (2 total, 0 dead)
Name: 192.168.200.1:50010
Decommission Status : Normal
Configured Capacity: 65501978624 (61 GB)
DFS Used: 28920520704 (26.93 GB)
Non DFS Used: 35444080640 (33.01 GB)
DFS Remaining: 1137377280(1.06 GB)
DFS Used%: 44.15%
DFS Remaining%: 1.74%
Last contact: Mon Aug 12 22:19:15 JST 2013
Name: 192.168.200.100:50010
Decommission Status : Normal
Configured Capacity: 31181533184 (29.04 GB)
DFS Used: 8769536 (8.36 MB)
Non DFS Used: 3722293248 (3.47 GB)
DFS Remaining: 27450470400(25.57 GB)
DFS Used%: 0.03%
DFS Remaining%: 88.03%
Last contact: Mon Aug 12 22:19:17 JST 2013
上記の例で言えば、192.168.200.100が追加したdatanode。
使用量がまだ8MBしかないことが分かるだろうか。
replication数を2にしたので、ゆくゆくは192.168.200.1と同じ程度の使用量になるはず。
しばらく放置が必要。
(いま気がついたけど、“Under replicated blocks”、つまり所定のreplicationに満たないblockの数が5…)
擬似分散→擬似分散+1の効果
効果は劇的。
もともと2時間半かかっていたものが1時間半に短縮できた。
下記はtimeの結果。上が擬似分散、下が擬似分散+1。
real 147m34.258s
user 0m6.835s
sys 0m2.233s
real 82m59.557s
user 0m5.624s
sys 0m1.604s
ああもっとdatanode増やしたい。
関連エントリ
[FreeBSD] Hadoopのportsからのインストール
[FreeBSD] portsのHadoopで分散(x-distributed)モードを動かす準備
[Hadoop]Hadoop 擬似分散(Psuedo-distributed)モードの設定
[Hadoop]擬似分散モードで実験